
Essential Kubernetes Autoscaling Guide: Karpenter Monitoring with Prometheus 🚀
Karpenter is an open-source project by AWS, simplifies Kubernetes cluster scaling by automating the provisioning and decommissioning of nodes based on resource demands. However, to unleash the full potential of Kubernetes autoscaling, monitoring its performance is essential. This article explores the significance of monitoring Karpenter with Prometheus and the potential consequences of neglecting this crucial aspect with real hands on examples and Grafana dashboards.
Understanding Karpenter and Its Role in Kubernetes Autoscaling
Karpenter acts as an intelligent layer that sits on top of Kubernetes, handling node provisioning and decommissioning seamlessly. It analyzes the resource utilization of a cluster and scales the infrastructure up or down accordingly. This dynamic Kubernetes autoscaling capability ensures cost-effectiveness and efficient resource utilization.
The Role of scaling Prometheus in Monitoring Karpenter:
Prometheus, a leading open-source monitoring and alerting toolkit, provides a robust solution for monitoring Kubernetes clusters. When integrated with Karpenter, Prometheus collects crucial metrics, such as node utilization, pod metrics, and scaling events, enabling administrators to gain insights into the performance of the Kubernetes autoscaling processes.
Karpenter provides many useful metrics for every component such as:
- Consistency metrics.
- Disruption Metrics.
- Interruption Metrics.
- Node claims Metrics.
- Provisioner Metrics.
- Node pool Metrics.
- Nodes Metrics.
- Pods Metrics.
- Cloud provider Metrics.
You can find the full list of metrics with explanations in the documentation. All you need to do to start scraping Karpenter metrics is enable the serviceMonitor in the Karpenter helm chart by setting: “serviceMonitor.enabled=true“

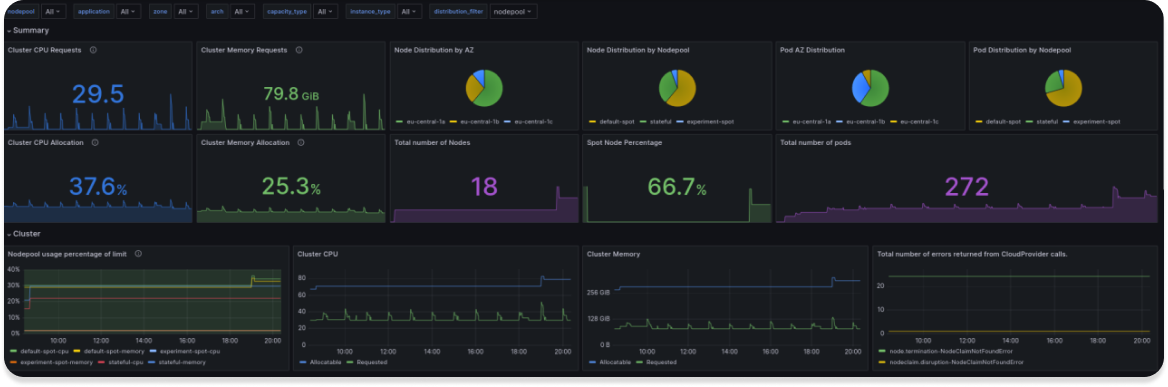
We have already prepared a dashboard that you can download from grafana.com or import with ID 20398, but be aware it works with >=0.33 version of Karpenter, in the previous version some metrics had different names.
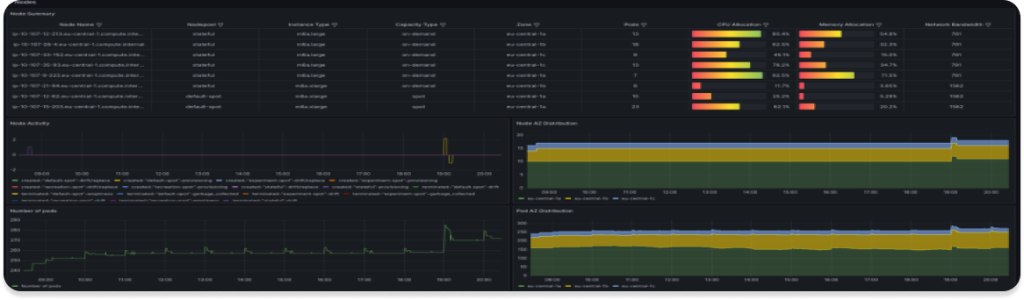
Visualization is of course good for analysis, but we need to immediately find out that something is wrong with the infrastructure, so let’s create several alerts. PrometheusRules will help us with that.
In this article I will show you 3 alerts to scale Promethes but you can create as much as you need.
The First one will show us the situation we were in, when new nodes could not register in the cluster, for that we will use 2 metrics:
- karpenter_nodeclaims_launched (Number of nodeclaims launched in total by Karpenter. Labeled by the owning nodepool.)
- karpenter_nodeclaims_registered (Number of nodeclaims registered in total by Karpenter. Labeled by the owning nodepool.)
Usually they should be the same and if this is not the case then something has happened
The Second one will show us that we are approaching the CPU or Memory limit set on the Nodepool
- karpenter_nodepool_usage(The nodepool usage is the amount of resources that have been provisioned by a particular nodepool. Labeled by nodepool name and resource type.)
- karpenter_nodepool_limit(The nodepool limits are the limits specified on the nodepool that restrict the quantity of resources provisioned. Labeled by nodepool name and resource type. karpenter_nodepool_usage)
In the Third, we want to find out the situation in which the Karpenter cannot communicate with the Cloud provider
- karpenter_cloudprovider_errors_total(Total number of errors returned from CloudProvider calls.)
Finally PrometheusRule File will be next:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: karpenter
heritage: Helm
release: prometheus
name: karpenter
spec:
groups:
- name: karpenter
rules:
- alert: KarpenterCanNotRegisterNewNodes
annotations:
description: |-
Karpenter in the nodepool {{ $labels.nodepool }} launched new nodes, but some of the nodes did not register in the cluster during 15 minutes.
summary: Problem with registering new nodes in the cluster.
expr: |
sum by (nodepool) (karpenter_nodeclaims_launched) - sum by (nodepool)(karpenter_nodeclaims_registered) != 0
for: 15m
labels:
severity: warning
- alert: KarpenterNodepoolAlmostFull
annotations:
description: |-
Nodepool {{ $labels.nodepool }} launched {{ $value }}% {{ $labels.resource_type }} resources of the limit.
summary: Nodepool almost full, you should increase limits.
expr: |
sum by (nodepool,resource_type) (karpenter_nodepool_usage) / sum by (nodepool,resource_type) (karpenter_nodepool_limit) * 100 > 80
for: 15m
labels:
severity: warning
- alert: KarpenterCloudproviderErrors
annotations:
description: |-
Karpenter received an error during an API call to the cloud provider.
expr: |
increase(karpenter_cloudprovider_errors_total[10m]) > 0
for: 1m
labels:
severity: warning
Of course, it’s not worth stopping at only 3 alerts, you can create different alerts your suit your needs.
Conclusion:
In embracing the power of Karpenter and Prometheus, we’ve not only streamlined our Kubernetes autoscaling processes but also fortified our infrastructure with a robust monitoring framework. The scaling Prometheus into our ecosystem has empowered us with a comprehensive dashboard that paints a vivid picture of our cluster’s health, providing real-time insights into node utilization, pod metrics, and scaling events.
The dashboard acts as our watchtower, offering a bird’s-eye view of the entire Kubernetes landscape. With a quick glance, we can assess resource utilization, identify potential bottlenecks, and track the performance of our Kubernetes autoscaling mechanisms. This newfound visibility has not only optimized our resource allocation but also enabled us to proactively address any anomalies before they escalate into critical issues.
However, the power of Prometheus extends beyond mere observation. The alerting capabilities embedded within Prometheus serve as our vigilant guardians, tirelessly monitoring the system for any deviations from the norm. As a result, we are no longer in the dark about potential scaling delays, performance degradation, or security threats. Instead, we receive timely notifications, allowing us to spring into action and maintain the integrity and security of our Kubernetes environment.
For any technical assistance or further inquiries, whether for business or personal use, we are here to help, Feel free to reach out to us at info@regitsfy.com




{kind=link}
This article kept my attention from start to finish!
The site’s design makes it a joy to explore.